Architecture boundaries


Goal of architecture
It is often said that software architect is not a programmer per se, and focuses only on high-level issues. Software architects are programmers, but on top of that they guide code to be better designed to maximize productivity.
Design focuses on code to be easy to develop, deploy, operate and maintain. It doesn't mean that well designed application satisfies the requirements in terms of proper behavior. There can be a well designed application which does not work properly, but we see terribly designed applications that work properly much more often.
Another responsibility of an architect is to keep as many options as possible open. But what does it mean to keep options open?
It means to delay decisions about architectural details as long as possible. Details are basically everything but policy, for example IO, databases, frameworks and so on.
Single responsibility principle (and Common closure principle) should be applied to system as well, so we can separate things that change for different reasons. For example validation of input fields is not very tied to the application, but for example calculation of interest on an account and the counting of inventory is closely tied with the domain. These two rules will change for different reasons and in different rates, so we should separate them.
If we decouple system into layers, we should separate UI, and the I/O (for example database) from business rules, which can be divided into application independent business rules, and domain business rules. We call this layers the horizontal layers of system.
We can also split the application into separate use cases, which should be separated, because they change for different reasons as well. Separating the application by use cases is called vertical layering.
Policy
Policy is where the true value of system lays. It contains all business logic that is unique to the system. System should treat it as its most essential element. All the other things are just details and they should be irrelevant to that policy.
Duplication
I think we all can agree that duplication in software is not a good thing. It makes changing code more complicated. But there is another kind of duplication called accidental duplication, which can cause much more problems when we try to extract and join them.
It happens when there are same pieces of code on multiple places, but they change at different rates and for different reasons. They are not true duplicates. Over the time, they can become very distinct from each other.
Boundaries
Software architecture is all about drawing lines between software elements that should be separated. We call this lines boundaries. Some of them exist even before first lines of code are written, so we can protect business logic from pollution by the details.
Boundaries should separate things that matter from things that don't. The database doesn't matter to GUI, so we should separate them. Also the database doesn't matter to business rules, so there should be a boundary as well.
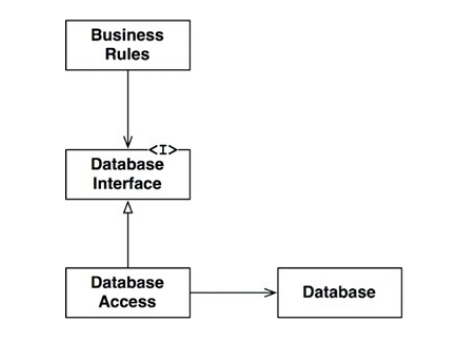
Some programmers may disagree with this picture. Particularly the part that tells that the database doesn't matter to the business rules. The boundary is drawn by the Database Interface, which only specifies the API that communicates with the database, but not any of the details behind it. This decouples business rules from database we chose which ultimately leads to a lot more flexibility. We can plug our current database out and implement a whole different adapter for the interface a lot easier than if our business rules have depended on it. That is the main advantage of correctly used boundaries.
The whole point of separating our source code dependencies by boundaries is that we can make changes and recompile/redeploy only the modules that are dependent on that module.
For example in our image, if we have made changes to Database Access module, there would be no need to recompile the interface module and thus there is no need to recompile our business rules, which is a crucial advantage.
Policy and level
The way our software system describes how the inputs are transformed to outputs is called policy. Policy represent our business rules. In most systems, there are many different policies. Our goal should be to keep these separated from one another and group the ones that change for same reasons together.
So how does level fit in all this? Shortest definition is that it's the distance from the inputs and outputs. This means that policies that are close to inputs and outputs are low-level policies, and on the other hand ones that are furthest from I/O are high-level policies.
This should make more sense if we show it on a diagram
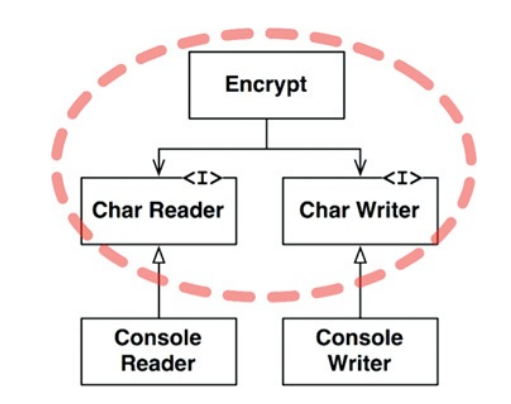
The encrypt class and its interfaces are the high-level policy of the system. Implementations of these interfaces are low-level details, which have external and possibly environment specific dependencies.
The best thing about this is that our encryption policy does not care about how reader or writer works. And why should it? If we try to read from file, or network, it should not affect the way we encrypt data. We make sure it doesn't by decoupling it.
Business rules
What are business rules, anyway? We can define them as rules that save or produce money for business, regardless if they are implemented in real world or as a set of computer instructions. They are often called critical business rules and they operate on (critical) business data. If we represent these data with an object, we call it Entity. Its properties would be business data, and methods represent business rules:

These kind of objects should be at the highest level and should not depend on other concerns of system: database, UI, or 3rd party libraries.
Use cases
Some business rules are more complicated than simple entity. They can describe more complicated usages of the system. Its rules are also application specific - that means they can contain application validations, persistence of the data and sending notifications via emails.
An important piece of information is also that the use case should have no knowledge about the user interface and nor have the knowledge about the details of how persisting the data works (what kind of database service, etc.). Same as entities have no knowledge of use cases, use cases have no knowledge of the UI and persistence details.
Conclusion
We went over what is the main goal of system architecture. A good architect makes system easy to develop, deploy, operate and maintain. He keeps the options open, making it agile to ever-changing business requirements.
Then we mentioned software boundaries and how they satisfy the single responsibility principle by layering the levels and keeping their dependencies on each other only in one direction - from low to high-level. We split these layers into two categories: policy and details.
Thank you very much for taking your valuable time to read this. I hope this article has helped you deepen your understanding of mentioned concepts.