Programming paradigms

The second part of the book dives right in to the heart of the architecture - the code, particularly the programming paradigms.
There are three paradigms included, and according to book there is very little possibility that any more does exist.
The three are:
- Structured programming
- Object-oriented programming
- Functional programming
Structured Programming
This is the first applied paradigm (but interestingly not the first invented), discovered by Edsger W. Dijkstra in 1968.
In those days, computers were very limited and slow by today's standards, programs were written in binary and the input took the physical form of punched cards. Dijkstra recognized, that programming is quite hard and that programmers make mistakes quite often.
His solution was to apply mathematical proofs to prove structures and then use them together to code that would be proven correct again. During this he discovered that some cases of usages of goto statements prevent modules from recursive decomposition. That means some usages led the code to be impossible to divide into smaller and independent units.
But not all usages had this problem. These were the ones that represented simple selection and iteration control structures: if-then-else and do-while.
This led to a letter he wrote to the editor of ACM, the legendary "Go To Statement Considered Harmful.". At first, other programmers didn't take this critique very well. Luckily, goto statement eventually disappeared (there are some languages that still have it, but in more restricted form).
Even though his idea that every program should be mathematically proved didn't caught very well, his contributions by applying structured programming were huge to the community.
Nonetheless, structured programming revolutionized the way we structured our programs, because suddenly we had opportunity for functional decomposition. That means, that we can decompose our modules into smaller parts recursively as the scale grows. Then we can prove that these units work as expected with software testing. Or can we?
Dijkstra himself told:
Program testing can be used to show the presence of bugs, but never to show their absence!
But what does this mean? Uncle Bob compared testing to the way we prove scientific laws. In short, we can't prove them in sense of mathematical proofs. They are falsifiable, but not provable. It means we assume that law is correct until someone manages to prove it false. Same applies to software. We assume that our provable unit is correct and we try to prove it isn't by the usage of software testing.
So all in all, structured programming is an ability to decompose problem into small falsifiable units.
Object-oriented programming
It's hard to define what exactly does OOP mean. But we can assume that code is object oriented when it contains a balanced mixture of these three ingredients: encapsulation, inheritance and polymorphism. So let's examine these.
Encapsulation
Every OO language should provide an easy way of encapsulating data and functions. That way we can hide implementation details, which is in many cases unnecessary knowledge for the outer world. This separation is drawn by public and non-public members of class.
But encapsulation is not OOP specific, consider this C language example from the book:
// point.h
struct Point;
struct Point* makePoint (double x, double y);
double distance (struct Point *p1, struct Point *p2);// point.c
#include "point.h"
#include <stdlib.h>
#include <math.h>
struct Point {
double x,y;
};
struct Point* makepoint(double x, double y) {
struct Point* p = malloc(sizeof(struct Point));
p->x = x;
p->y = y;
return p;
}
double distance(struct Point* p1, struct Point* p2) {
double dx = p1->x - p2->x;
double dy = p1->y - p2->y;
return sqrt(dx*dx+dy*dy);
}This is a very clear example of what encapsulation is. The header file doesn't know anything about the members of Point structure, and there's no reason it should. This actually can't be archieved in OO language. To declare the class, all it's members must be explicitly declared with it as showed below in example of C++ code from the book:
// point.h
class Point {
public:
Point(double x, double y);
double distance(const Point& p) const;
private:
double x;
double y;
};// point.cc
#include "point.h"
#include <math.h>
Point::Point(double x, double y): x(x), y(y) {}
double Point::distance(const Point& p) const {
double dx = x-p.x;
double dy = y-p.y;
return sqrt(dx*dx + dy*dy);
}It seems like OOP doesn't provide better encapsulation than declarative C language.
Inheritance
Most of us consider inheritance to be a feature of OO design. But the book says otherwise and backs it up with pretty good argumentation.
It defines inheritance as redeclaration of a group of variables and functions within an enclosing scope. That's another thing that can be done in C language.
Consider this code to be an extension to previous point.h code:
// named_point.h
struct NamedPoint;
struct NamedPoint* makeNamedPoint (double x, double y, char* name);
void setName (struct NamedPoint* np, char* name);
char* getName (struct NamedPoint* np);//named_point.c
#include "named_point.h"
#include <stdlib.h>
struct NamedPoint {
double x, y;
char* name;
}
struct NamedPoint* makeNamedPoint(double x, double y, char* name) {
struct NamedPoint* p = malloc(sizeof(struct NamedPoint));
p->x = x;
p->y = y;
p->name = name;
return p;
}
void setName(struct NamedPoint* np, char* name) {
np->name = name;
}
char* getName(struct NamedPoint* np) {
return np->name;
}// main.c
#include "point.h"
#include "named_point.h"
#include <stdio.h>
int main (int ac, char** av) {
struct NamedPoint* origin = makeNamedPoint(1.0, 1.0, "origin");
struct NamedPoint* upperRight = makeNamedPoint(1.0, 1.0, "upperRight");
printf("distance=%f\n",
distance(
(struct Point*) origin,
(struct Point*) upperRight));
}Let's analyze this code. The members have to be redefined in exact order that is defined in Point structure. That way we can use NamedPoint in its context. In OOP this is archievable by any derivative of a given class implicitly. In our code we need to explicitly tell distance function to act as if Point was provided by casting.
We must give credit to OOP that it made inheritance convenient, but the concept was definitely not new.
Polymorphism
There is a nice example of polymorphism usage pointed out in the book. It is also in C language, particularly the implementation of STDIN and STDOUT devices.
Consider this code:
#include <stdio.h>
void copy() {
int c;
while ((c=getchar()) != EOF)
putchar(c);
}This code is device independent - that means that there are many types of STDIN and STDOUT devices, but it somehow doesn't matter to this piece of code.
But how does it work? The UNIX system requires that IO all device drivers provide five standard functions: open, close, read, write and seek and their signatures must be identical for all IO drivers. This is defined by the FILE data structure:
struct FILE {
void (*open)(char* name, int mode);
void (*close)();
int (*read)();
void (*write)(char);
void (*seek)(long index, int mode);
};We can see that it contains pointers to functions that meet the criteria defined by the UNIX system. The IO driver must define these functions, load them into a FILE data structure and provide this data structure to the program.
Even if this means that we had polymorphism before OO languages, it wasn't very safe or convenient. They make use of polymorphism almost trivial. This brings huge advantage over classic C style polymorphism.
We can safely say, that OOP imposes discipline on indirect transfer of control via polymorphism.
But what's so great about polymorphism?
Consider an example we stated earlier with the copy function. Suppose that we would need to use a different IO devices, for example we would want to copy from handwriting recognition device into speech synthesizer device. What changes we should make to the program to make it work this way?
The answer is none and we wouldn't even need to recompile the program. This is because program does not depend on these IO devices. As long as they implement all functions given by the FILE data structure, it's all working.
Dependency inversion
With the classical approach we have explicit control flow. The high level functions are calling the middle level functions, which are calling the low level functions. The dependency tree just follows flow of control.
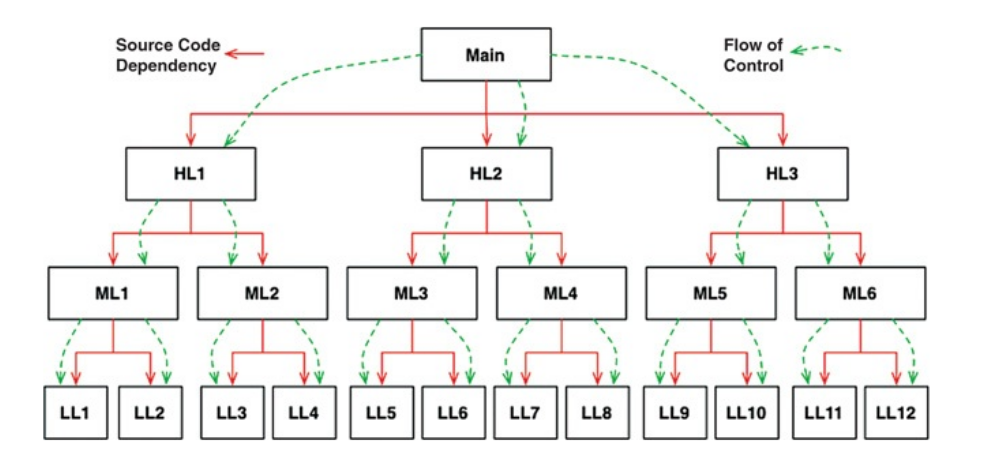
In this tree, every caller is forced to mention the module wtich contains the callee. The dependencies are dictated by flow of control.
When we introduce polymorphism into system, the dependency is inverted between caller and callee, thus the dependency inversion.
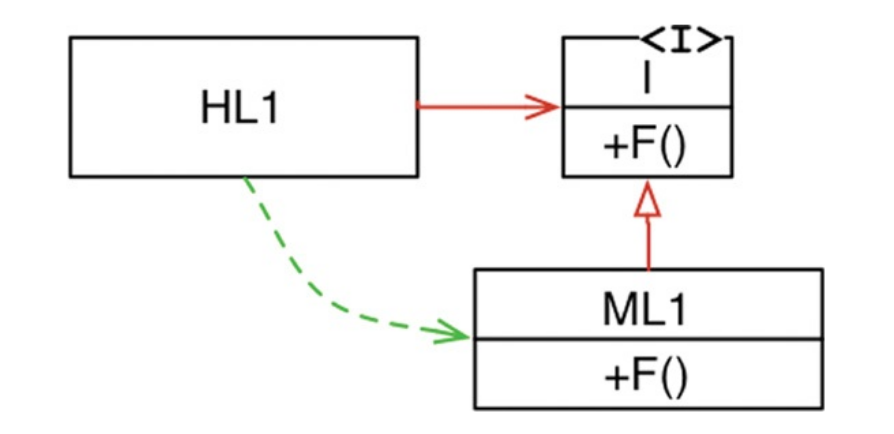
As we see in picture above, the high level module calls the function from mid level module, so the intent is the same as in the previous picture, but there is an interface inserted between them. Same flow happens at runtime, but the source code dependency points in opposite direction, compared to this flow.
This is great from the architectural point of view, because every dependency can be inverted.
But what is so great about that?
Consider image below:
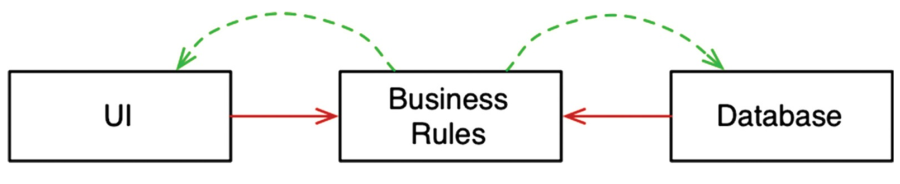
When we invert the dependance of business rules on the UI and database, they will become plugins for our business rules. The business logic will never have to mention either of them.
These three layers can even be separated into deployable units, because changes on one of them will never affect others, which means that they could be easily maintained by different teams independently.
That is the real power of the OOP, total control over the source code dependencies through the dependency inversion.
Functional Programming
First concept of functional programming based on l-calculus were invented in the 1930s by Alonzo Church, which even predates programming itself.
Example
Book gives us a great example of a comparison between OO and functional language by example of printing the squares of first 25 integers. Since the given functional language is Clojure, which I don't know anything about, I've prepared an example in Elixir, very unique and modern functional language.
First, let's see the implementation in Java, which is pretty straightforward:
public class Squint {
public static void main(String args[]) {
for (int i=0; i<25; i++) {
System.out.println(i*i);
}
}
}In elixir, we would implement this as follows:
IO.puts(Enum.join(Enum.map(Enum.to_list(0..24), &(&1*&1)), "\n"))This is not very readable though, so we better use some syntactic sugar elixir gives us and format it a little bit:
# Take range of first 25 integers
0..24
# Convert it to list
|> Enum.to_list
# Transform every item to its square value
|> Enum.map(&(&1*&1))
# Join them separated by new lines
|> Enum.join("\n")
# Print to STDOUT
|> IO.putsAs you can see, the flow of data is very explicit. At first, we must take range of first 25 integers and convert it into list. Then we need to transform every item to its square. This is handled by map function, which calls the callback on every item. Then we join the output to string divided by new line characters and print it to STDOUT.
There is one very important difference between the Elixir and Java examples. Java one uses a mutable variable i. That means that it changes its state during execution. No such variables exist in functional programs. The variables are initialized, but their are never modified - that's the concept of immutability.
Immutability and architecture
Immutability of variables is very beneficial from an architectural standpoint. Almost all problems with concurrency are caused by mutability of variables: race conditions, deadlock conditions and so on.
Taming mutability
There are some cases when system must allow mutability. A compromise has to be made, and the mutability must happen under strict conditions in a mutable component separated from others. This component is allowed to mutate the state of variables in memory.
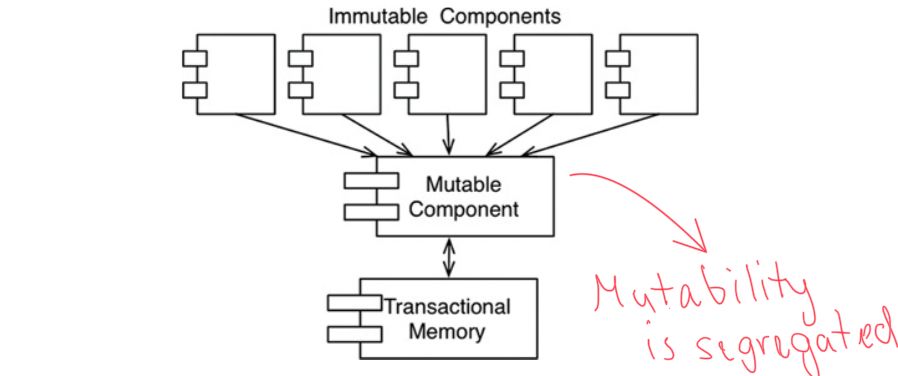
Event sourcing
The more processing power and memory are rising, the less we need mutability.
Most problems that require system to change its resources can be solved with event sourcing.
An example of this can be a system that maintains account balances for its users. Instead of storing the account balance, we compute it on demand as the sum of all saved transactions. This can be archieved without mutable variables.
This may sound absurd, since the number of transactions will grow in time and the time of computation will grow linearly with it.
Event sourcing is basically a strategy when we store the transactions instead of the state to avoid mutability.
To solve the problem of the linear complexity we can precompute the balance in a reasonable periods and only add up transactions created since last precomputation.
Downside of this is that storing every transaction takes up quite a lot of storage. But the benefits are profound - nothing ever gets updated or deleted in this system, so there cannot be any concurrent update issues.
Conclusion
We introduced three paradigms:
- Structured programming - discipline imposed upon direct transfer of control
- Object-oriented programming - discipline imposed upon indirect transfer of control.
- Functional programming - disciplind imposed upon variable assignment
Interesting thing about this is that none of these paradigms adds new capabilities to the way we write code, but they are based on restriction.
Software in its core is same as it was in the times when Alan Turing wrote the first lines of it - compose of sequence, selection, iteration and indirection.